Multilingual Translation
natural language
table of contents
- introduction
- machine translation
- parallel text
- subword splitting
- low-resource NMT
- multilingual translation
- reverse training strategy
Sicilian language
Our discussion so far has focused on a dataset of Sicilian-English parallel text. This page augments our dataset with parallel text in other languages to enable multilingual translation. It explains how we can train a single model to translate between multiple languages, including some for which there is little or no parallel text.
In our case, we can obtain Sicilian-English parallel text from the issues of Arba Sicula, but finding Sicilian-Italian parallel text is difficult.
Nonetheless, we trained a model to translate between Sicilian and Italian without any Sicilian-Italian parallel text at all (i.e. "zero shot" translation) by including Italian-English parallel text in our dataset. Then, to improve translation quality between Sicilian and Italian, we implemented a simple version of the "bridging strategy" proposed by Fan et al. (2020) and added Sicilian-Italian-English homework exercises to our dataset.
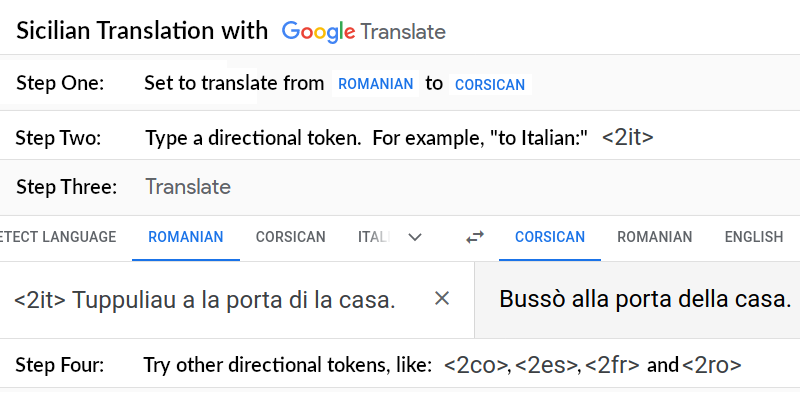
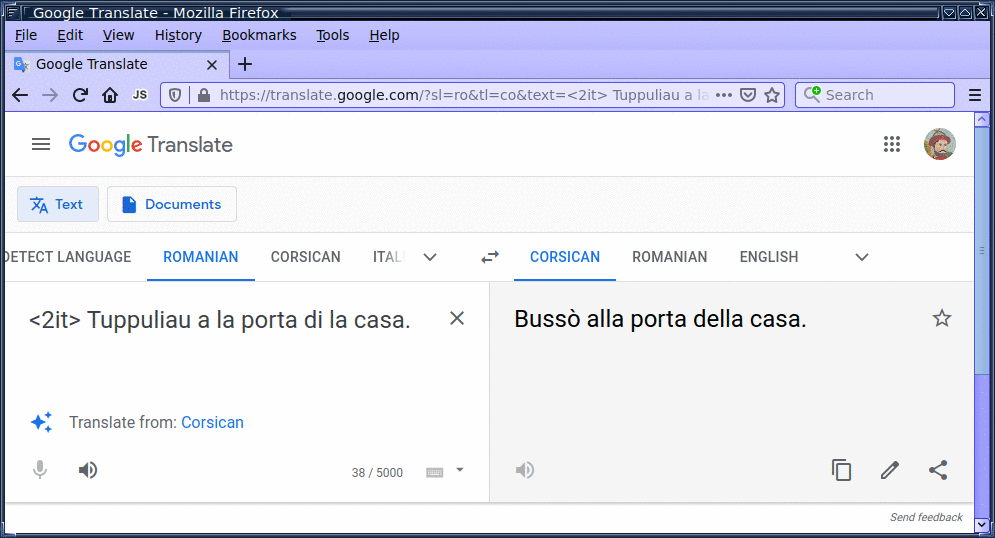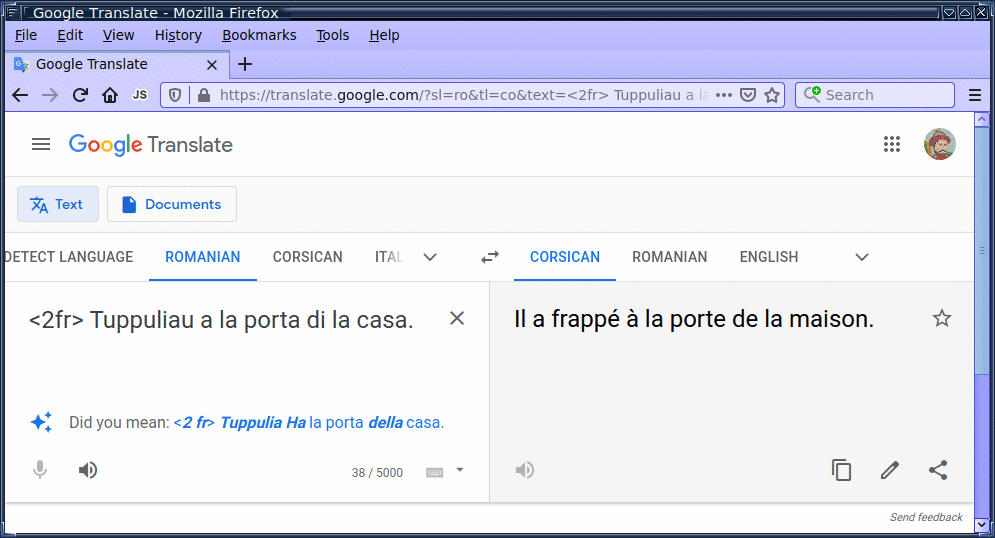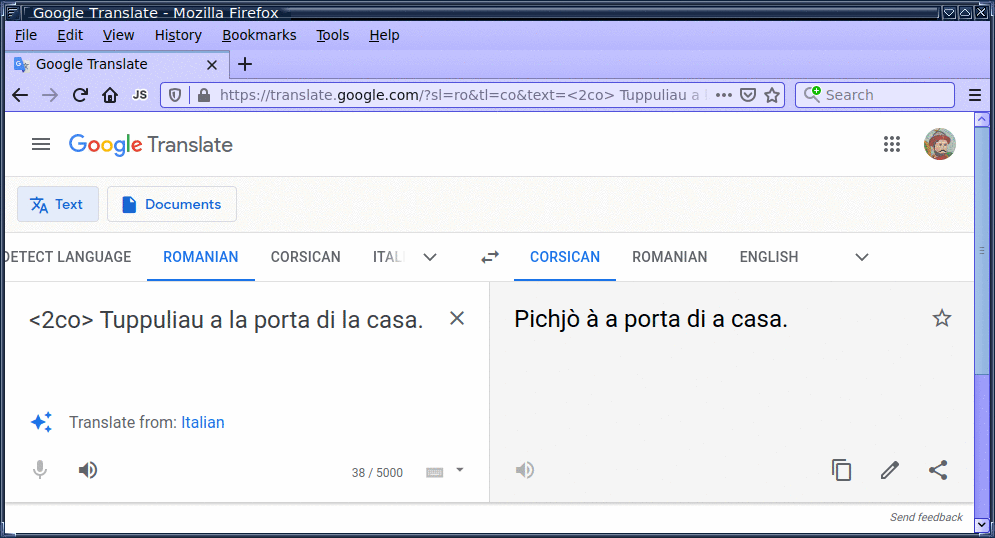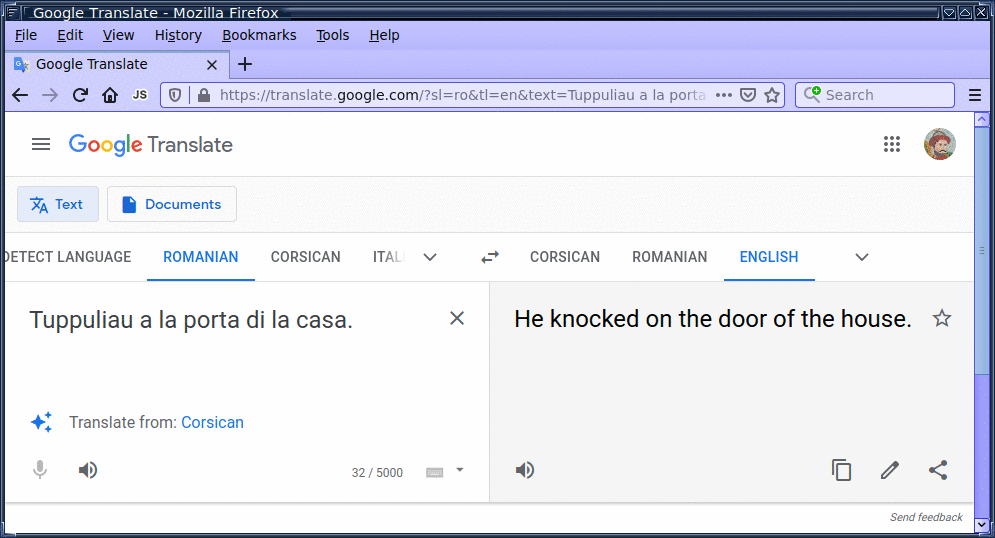
To enable multilingual translation, we followed Johnson et al. (2016) and placed a directional token – for example, <2it> ("to Italian") – at the beginning of each source sequence. The directional token enables multilingual translation in an otherwise conventional model.
It's an example of transfer learning. In our case, as the model learns to translate from Italian to English, it also learns to translate from Sicilian to English. And as the model learns to translate from English to Italian, it also learns how to translate from English to Sicilian.
More parallel text is available for some languages than others however, so Johnson et al. also studied the effect on translation quality and found that oversampling low-resource language pairs improves their translation quality, but at expense of quality among high-resource pairs.
Importantly however, the comparison with bilingual translators holds constant the number of parameters in the model. Arivazhagan et al. (2019) show that training a larger model can improve translation quality across the board.
More recently, Fan et al. (2020) developed the strategies to collect data for and to train a model that can directly translate between 100 languages. Previous efforts had resulted in poor translation quality in non-English directions because the data consisted entirely of translations to and from English.
To overcome the limitations of English-centric data, Fan et al. strategically selected pairs to mine data for, based on geography and linguistic similarity. Training a model on such a more multilingual dataset yielded very large improvements in translation quality in non-English directions, while matching translation quality in English directions.
Given such potential to expand the directions in which languages can be translated and to improve the quality with which they can be translated, an important question is what the model learns. Does it learn to represent similar sentences in similar ways regardless of language? Or does it represent similar languages in similar ways?
Johnson et al. examined two trained trilingual models. In one, they observed similiar representations of translated sentences, while in the second they noticed that the representations of zero-shot translations were very different.
Kudugunta et al. (2019) examined the question in a model trained on 103 languages and found that the representations depend on both the source and target languages and they found that the encoder learns a representation in which linguistically similar languages cluster together.
In other words, because similar languages learn similar representations, our model would learn Sicilian-English better from Italian-English data than from Polish-English data. And other Romance languages, like Spanish, would also be good languages to consider.
We can collect some of that parallel text from the resources at OPUS, an open repository of parallel corpora. Because it contains so many language resources, Zhang et al. (2020) recently used it to develop the OPUS-100 corpus, an open-source collection of English-centric parallel text for 100 languages.
Because it's a "rough and ready" massively multilingual dataset, it highlights some of the challenges facing massively multilingual translation. In particular, Zhang et al. show that a model trained with a vanilla setup exhibits off-target translation issues in zero-shot directions. In the English-centric case, that means the model often translates into the wrong language when not translating to or from English.
Zhang et al. tackle this challenge by simulating the missing translation directions. They first observe that Sennrich, Haddow and Birch's (2015) method of back-translation "converts the zero-shot problem into a zero-resource problem" because it creates synthetic source language text. They then observe that this synthetic source language text simulates the missing translation directions.
The only obstacle is scalability. In a massively multilingual context, there are thousands of translation directions, which requires prohibitively many back-translations. To overcome this obstacle, Zhang et al. incorporate back-translation directly into the training process. And their final models exhibit improved translation quality and fewer off-target translation errors.
So we're excited about the potential for multilingual translation to improve translation quality and to create new translation directions for the Sicilian language.
Using the Italian-English subset of Farkas' Books data, multilingual translation greatly improved the quality of translation between Sicilian and English (as shown on the scoreboard of our low-resource NMT page).
And after enabling zero-shot translation between Sicilian and Italian with the technique proposed by Johnson et al., we improved translation quality between Sicilian and Italian with Fan et al.'s "bridging strategy."
In our case with only three languages, we built a simple bridge between Sicilian, English and Italian by translating 4,660 homework exercises from the Mparamu lu sicilianu (Cipolla, 2013) and Introduction to Sicilian Grammar (Bonner, 2001) textbooks.
As shown on the scoreboard, this technique yielded translation quality between Sicilian and Italian that's almost as good as translation quality between Sicilian and English, for which we have far more parallel text.
So come to Napizia and explore the multilingual features of our Tradutturi Sicilianu!
Copyright © 2002-2026 Eryk Wdowiak

